STAT478 S1 2016: Special Topic in Scalable Data Science
 Databricks Academic Partners Program
Databricks Academic Partners Program
 Amazon Web Services Educate
Amazon Web Services Educate
The 2016 instance of this course finished on June 30 2016.
To learn Apache Spark for free try databricks Community edition by starting from: https://databricks.com/try-databricks.
All course content can be uploaded for self-paced learning from the following URL: this 2016/Spark1_6_to_1_3/scalable-data-science.dbc archive to your free Databricks Community Edition: https://community.cloud.databricks.com.
You may also read the scalable-data-science Gitbook and fork your own to keep the course contents up to date from scalable-data-science github and its scalable-data-science github pages.
Course Coordinator
Raazesh Sainudiin
Office Hours for Semester 1 2016: Mondays and Fridays 1pm-2pm in Erskine 724
Time and Place for Interaction
- Physical
- Time:
- 4:30PM to 6:00PM for the weekly Combined Lecture-Lab Meeting
- 6:00PM-6:30PM is the period for direct assistance with labs (this is optional for faculty and industry students)
- Place:
- Time:
- Cyber (mostly streaming with minimal interaction)
- Join the webcast from PC, Mac, Linux, iOS or Android at https://canterbury.zoom.us/j/787338741.
- Catch-up on the lab-lectures from the scalable-data-science-2016 Playlist
- Stay in touch via Christchurch Apache Spark Meetup.
The course got some publicity through the following news feeds:
math.canterbury.ac.nz,
educators.co.nz,
scoop.co.nz,
itbrief.co.nz,
computerworld.co.nz.
All course materials will be made available through the Databricks Cloud that are also locally browsable.
To login to databricks, our cloud-computing infrastructure, go to http://www.math.canterbury.ac.nz/databricks.
Course materials as cloud-uploadable and locally browsable .html files:
You may just click the links below and browse the lab/lecture notebooks on a web browser (without logging into databricks). Note that links to other notebooks will not work when locally browsing, but links to public URLs, including videos will work (especially if you Right-Click and "open Link in new TAB").
- Week 1: Introduction to Scalable Data Science, Why Spark? and Crash Course in Scala
- Week 2: Spark Essentials, Transformations and Actions with Resilient Distributed Datasets and a Word Count of All US State of the Union Addresses until 2016
- Week 3: SparkSQL for Extracting, Transforming, Loading and Interactive Exploration of Data (Diamond features with price, Powerplant features with power output and Wikipedia Clickstreams)
- 2016/S1/week3/04_SparkSQLIntro/007_SparkSQLIntroBasics.html
-
HOMEWORK EXERCISES
- 2016/S1/xtraResources/ProgGuides1_6/sqlProgrammingGuide/000_sqlProgGuide.html
- 2016/S1/xtraResources/ProgGuides1_6/sqlProgrammingGuide/001_overview_sqlProgGuide.html
- 2016/S1/xtraResources/ProgGuides1_6/sqlProgrammingGuide/002_gettingStarted_sqlProgGuide.html
- 2016/S1/xtraResources/ProgGuides1_6/sqlProgrammingGuide/003_dataSources_sqlProgGuide.html
- 2016/S1/xtraResources/ProgGuides1_6/sqlProgrammingGuide/004_performanceTuning_sqlProgGuide.html
- 2016/S1/xtraResources/ProgGuides1_6/sqlProgrammingGuide/005_distributedSqlEngine_sqlProgGuide.html
- 2016/S1/week3/05_SparkSQLETLEDA/008_DiamondsPipeline_01ETLEDA.html
- 2016/S1/week3/05_SparkSQLETLEDA/009_PowerPlantPipeline_01ETLEDA.html
- 2016/S1/week3/05_SparkSQLETLEDA/010_wikipediaClickStream_01ETLEDA.html
- Week 4: Unsupervised Clustering of 1 Million Songs via K-Means and Supervised Classification of Hand-written Digits via Decision Trees
- 2016/S1/week4/06_MLIntro/011_IntroToML.html
- 2016/S1/week4/07_UnsupervisedClusteringKMeans_1MSongs/012_1MSongsKMeans_Intro.html
- 2016/S1/week4/07_UnsupervisedClusteringKMeans_1MSongs/013_1MSongsKMeans_Stage1ETL.html
- 2016/S1/week4/07_UnsupervisedClusteringKMeans_1MSongs/014_1MSongsKMeans_Stage2Explore.html
- 2016/S1/week4/07_UnsupervisedClusteringKMeans_1MSongs/015_1MSongsKMeans_Stage3Model.html
- 2016/S1/week4/08_SupervisedLearningDecisionTrees/016_DecisionTrees_HandWrittenDigitRecognition.html
- Week 5: Non-distributed and Distributed Linear Algebra and Applied Linear Regression (compared with Gradient Boosted Regression Trees)
- Week 6: Spark Streaming, Twitter Collector, Top Hashtag Counter and Streaming Model-Prediction Server
- 2016/S1/week6/12_SparkStreaming/021_SparkStreamingIntro.html
- 2016/S1/week6/12_SparkStreaming/022_TweetCollector.html
- 2016/S1/week6/12_SparkStreaming/022_TweetGenericCollector.html
- 2016/S1/week6/12_SparkStreaming/023_TweetHashtagCount.html
- 2016/S1/week6/13_StreamingMLlib_ModelTuneEvaluateDeploy/024_PowerPlantPipeline_03ModelTuneEvaluateDeploy.html
- Week 7: Probabilistic Topic Modelling via Latent Dirichlet Allocation
- Week 8: Graph Querying in GraphFrames and Distributed Vertex Programming in GraphX
- Week 9: Deep Learning, Convolutional Neural Nets, Sparkling Water and Tensor Flow
- 2016/S1/week9/16_Deep_learning/030_Deep_learning.html
- 2016/S1/week9/17_SparklingWater/031_H2O_sparkling_water.html
- 2016/S1/week9/17_SparklingWater/032_Deep_learning_ham_or_spam.html
- 2016/S1/week9/18_sparklingTensorFlow/033_SetupCluster_SparkTensorFlow.html
- 2016/S1/week9/18_sparklingTensorFlow/034_SampleML_SparkTensorFlow.html
- Week 10: Scalable Geospatial Analytics in Magellan and Esri-Geometry-Api
- Weeks 11 and 12: Student Project Presentations
- Scalable Spatio-temporal Constraint Satisfaction, Map-matching and OpenStreetMap to GraphX, by Dillon George, undergradute computer science student, UC, Ilam.
- Trump Twitter Analytics, by Akinwande Atanda, PhD Student, Department of Economics, UC, Ilam.
- Deciphering Spider Vision, by Yinnon Dolev, PhD Student, School of Biological Sciences, UC, Ilam.
- High Order Spectral Clustering, by Xin Zhao, Senior Data Scientist, Research and Development, Wynyard Group.
- EEG Data Exploration, by Shansha Zhou, PhD Student, HITLab, UC, Ilam.
- Change Detection in Degree Corrected Stochastic BlockModel Graphs, by Shakira Suwan, Data Scientist, Research and Development, Wynyard Group.
- The Association of Tennis Professionals (ATP) graph, by Matthew Hendlass, Data Scientist, New Zealand Inland Revenue.
- Keystroke Biometric, by Andrey Konstantinov, Senior Software Systems Engineer, Research and Development, Wynyard Group.
- Random Matrices, by Dominic Lee, Principal Data Scientist, Research and Development, Wynyard Group.
- Movie Recommender using Alternating Least Squares by Harry Wallace, Postgraduate student UC, Ilam.
You may also read the course gitbook in preparation (currently displays all input cells but only markdown output cells).
Brief Course Description
Scalable data science is a technical course in the area of Big Data, aimed at the needs of the emerging data industry in Christchurch and those of certain academic domain experts across UC's Colleges, including, Arts, Science and Engineering. This advanced course uses Apache Spark, a fast and general engine for large-scale data processing via databricks to compute with datasets that won't fit in a single computer. The course will introduce Spark's core concepts via hands-on coding, including resilient distributed datasets and map-reduce algorithms, data frames and spark SQL on catalyst, scalable machine-learning pipelines in MLlib and vertex programs using the distributed graph processing framework of graphX. We will solve instances of real-world big data decision problems from various scientific domains.
To quickly learn about the computing platform read an introduction to Apache Spark. The course will cover topics from the first 8 of 9 Must-Have Skills to Land Top Big Data Jobs in 2015 and better prepare the student to take the spark-certified-developer exams that are available online.
Minimal prerequisites include some experience in python programming (COSC 121) and knowledge of 200 level linear algebra (MATH 203) and 100 level calculus with probability (MATH 103). Additional courses in Mathematics, Statistics or Computer Science will be helpful.
It is possible to do a summer project/ industrial internship in scalable data science in 2016/2017 if you take the honours course STAT478 in Semester 1 of 2016. UC students who are interested in such an opportunity should contact me before the term break in order to choose a course project that better serves the needs of an available industrial partner in Christchurch, Auckland or Wellington.
What is Scalable Data Science?
Scalable data science is all about analysing big data, real-world datasets that do not fit into any single computer. So one needs a cloud-computing platform, a managed distributed computing environment made up of a network of several tens or hundreds of computers, to analyse such big data. The linked picture below shows the highly inter-disciplinary nature of scalable data science.
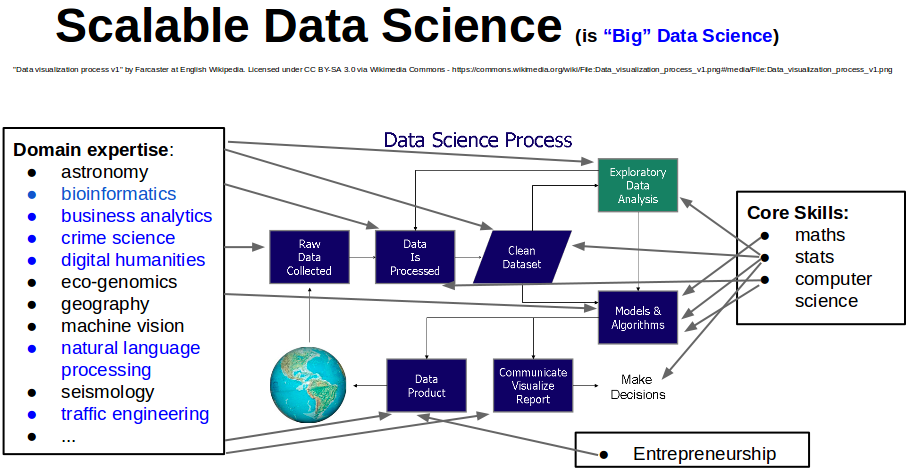
STAT478 S1 2016: Special Topic in Scalable Data Science (DETAILS)
Official Decription
The course will introduce Spark's core concepts via hands-on coding, including resilient distributed datasets and map-reduce algorithms, data frames and spark SQL on catalyst, and vertex programs using the distributed graph processing framework of graphX. The weekly labs will focus on solving real-world problems (using publicly available big datasets) such as:
- classification,
- regression,
- dimensionality reduction, model selection and feature engineering,
- vertex programs (distributed graph algorithms),
- geospatial data exploration and their integration with other data
- natural language processing tasks for social media analytics
- data integration across different data sources
There will be 90-minutes-long interactions for each of the 12 weeks involving some preparatory lectures, computer lab exercises and tutorials.
The computational labs will be done in the distributed computing infrastructure secured through the academic cloud-infrastructure grants from Databricks Academic Partners Program and Amazon Web Services Educate.
Learning Outcomes
Concrete learning outcomes will include:
- familiarity with map-reduce algorithms for processing big-data, including its robust clean-up via regular expressions
- basic skills to extract, transform and load data into distributed file systems such as hadoop
- working with structured data using dataframes and dynamic querying in sparkSQL on catalyst
- basic applications of some of the standard learning algorithms in Spark's machine learning and distributed graph processing libraries
- basic data science analytics pathways for the following common data types:
- structured text data (logs generated by machines, tabular data from various open data sources)
- (optional) geospatial data (and their integration with other types of data)
- unstructured text data (a collection of text documents)
- social media data
Students will be encouraged to show-case their completed labs (which will have plenty of opportunities for extending the basic labs in creative ways even after the course is completed) by publishing them in public GitHub repositories in order to directly appeal to their potential employers.
Assessment and moderation procedures
The course is extremely hands-on and therefore gives 50% of the final grade for attending each lab and completing it. Completing a lab essentially involves going through the cells in the cloned notebooks for each week to strengthen your understanding. This will ensure that the concept as well as the syntax is understood for the learning outcomes for each week. There are additional videos and exercises you are encouraged to watch/complete. These additional exercises will not be graded. You may use 1800-1830 hours to ask any questions about the contents in the current or previous weeks.
Each student will be working on a course project and present the findings to the class in the last week or two. The course project will be done in http://www.math.canterbury.ac.nz/databricks-projects. The project accounts for 50% of the final grade and will typically involve applying Spark on a publicly available dataset or writing a report to demonstrate in-depth understanding of appropriate literature of interest to the student’s immediate research goals in academia or industry. Oral presentation of the project will constitute 10% of the grade. The remaining 40% of the grade will be for the written part of the project, which will be graded for replicability and ease of understanding. The written report will be encouraged for publication in a technical blog format in public repositories such as GitHub through a publishable mark-down'd databricks notebook (this is intended to show-case the actual skills of the student to potential employers directly). Group work on projects may be considered for complex projects.
All course materials will be made available through the Databricks Cloud.
To login to databricks, our cloud-computing infrastructure, go to http://www.math.canterbury.ac.nz/databricks.
Course Archive (Past Instances)
Summer Project in Scalable Data Science (2015/2016)
It is possible to do a summer project in scalable data science that is more focussed on a specific big-data analytic task. This will essentially consist of a concentrated pathway through the original course proposal described below with the goal of analysing a specific publicly available big dataset of interest to the student.
Skeletal Notes for Summer Student Projects
To login to databricks: https://dbc-ad4cbabb-b84d.cloud.databricks.com/login.html
- Latent Dirichlet Allocation for Topic Modeling
- Scalable Geospatial Analytics
- Unsupervised Clustering
- graphX for graph-parallel Computing
- Streaming for Twitter Hashtags and lines containing a string
UC's Scalable Data Science programme has been successful in the Databricks Academic Partners Program and Amazon Web Services Educate.
These infrastructure grants allow scalable modules for big-data algorithmics and analytics to be incorporated into existing UC courses in the School across computational topics in optimisation, linear algebra and discrete mathematics. UC students and faculty can learn, teach and conduct academic research in state-of-the-art distributed and scalable computing environments at no infrastructural cost.
To login to databricks academic sandbox, our cloud-computing infrastructure for instructors and admins only, go to https://dbc-ad4cbabb-b84d.cloud.databricks.com.
To for raaz to login to raaz's databricks Community edition go to Raaz's DB CE.
Last modified on Monday, 24-Jul-2017 07:45:56 MST and served on Friday, 19-Apr-2024 18:54:32 MST.